Abstract
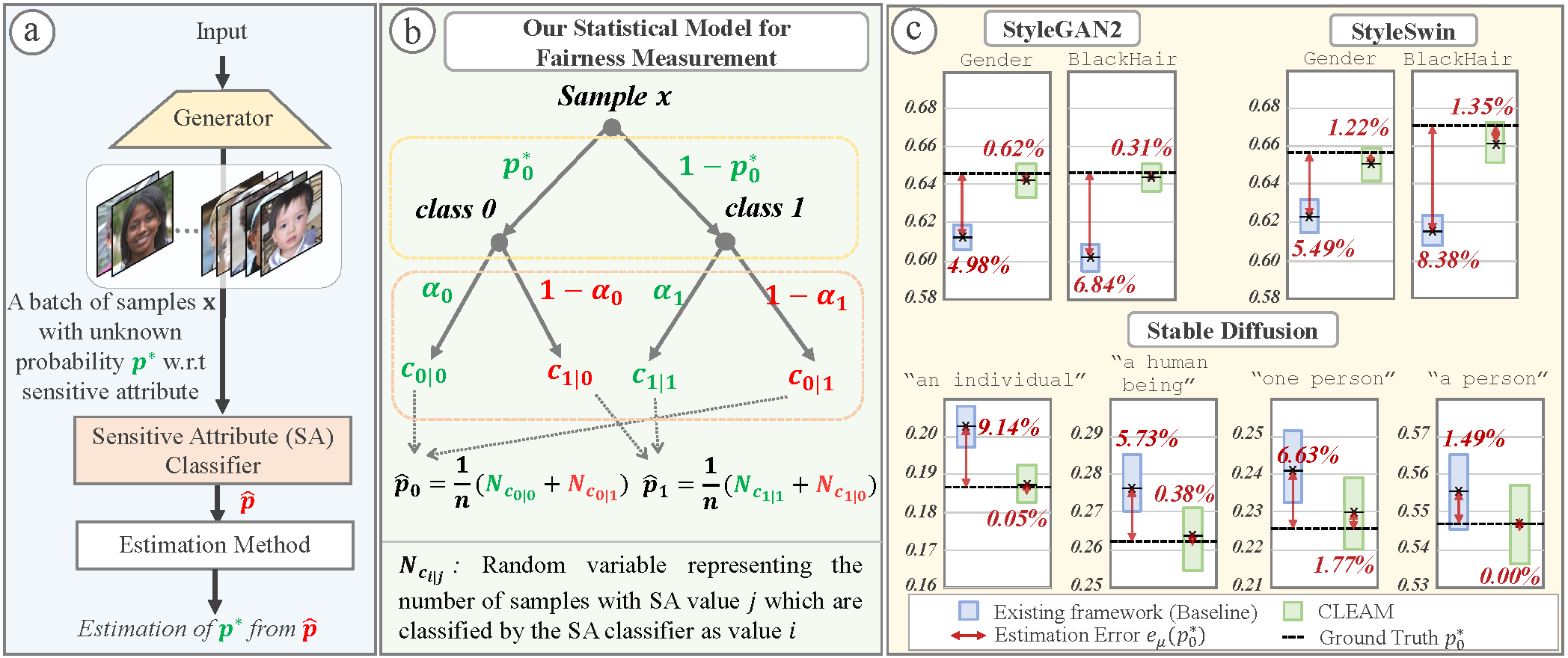
Recently, there has been increased interest in fair generative models. In this work, we conduct, for the first time, an in-depth study on fairness measurement, a critical component in gauging progress on fair generative models. We make three main contributions. First, we conduct a study that reveals that contrary to prior work’s assumption the existing fairness measurement framework has considerable measurement errors, even when highly accurate sensitive attribute (SA) classifiers are used. For example, a ResNet-18 for Gender with accuracy ≈ 97% could still result in an measurement error of 4.98%. This oversight raises concerns about the accuracy reported in previous works, where relative fairness improvement falls within these error margins. Second, to address this issue, we propose CLassifier Error-Aware Measurement (CLEAM), a new framework which uses a statisti- cal model to account for inaccuracies in SA classifiers. Our proposed CLEAM reduces measurement errors significantly, e.g., 4.98%→0.62% for StyleGAN2 w.r.t. Gender. CLEAM achieves this with minimal additional overhead. Third, we utilize CLEAM to measure fairness in important text-to-image generator and GANs, revealing considerable biases in these models that raise concerns about their applications. Code and reproducibility instructions are included in Supp.
Overview
|
|
Contributions1: We conduct a study to reveal that even highly-accurate SA classifiers could still incur significant fairness measurement errors when using existing framework.2: To enable evaluation of fairness measurement frameworks, we propose new datasets based on generated samples from StyleGAN, StyleSwin and SDM, with manual labeling w.r.t. SA 3: We propose a new and accurate fairness measurement framework, CLEAM, that accounts for SA classifier inaccuracies and provides point and interval estimates 4: Using CLEAM, we reveal considerable biases in several important generative models, prompting careful consideration when applying them for different applications. |
GenData Dataset
In our work, we present a new dataset based on generated samples from State-of-the-Art Generative models: StyleGAN2,StyleSwin and Diffusion models. In this dataset we provide labels for each samples w.r.t. Gender and BlackHair collecting utilizing Amazon MTurk. More specifically, our dataset contains ≈9k randomly generated samples based on the original saved weights and codes of the respective GANs, and ≈2k samples for four different prompts inputted in the SDM. These samples are then hand labeled w.r.t. the sensitive attributes. Then with these labeled datasets, we can approximate the ground-truth sensitive attribute distribution, p∗, of the respective GANs.


Figure 1: Examples of generated samples in GenDataw.r.t Gender i.e., LHS: Female samples and RHS: Male samples. |


Figure 2: Examples of generated samples in GenData w.r.t BlackHair i.e., LHS: No-BlackHair samples and RHS: BlackHair samples. |


Figure 3: Examples of rejected generated samples in GenData i.e., LHS: StyleGAN2 samples and RHS: StyleSwin samples. |
BibTeX
@article{teo2024measuring,
title={On measuring fairness in generative models},
author={Teo, Christopher and Abdollahzadeh, Milad and Cheung, Ngai-Man Man},
journal={Advances in Neural Information Processing Systems},
volume={36},
year={2024}
}
}